Source - Adrian Cantrill
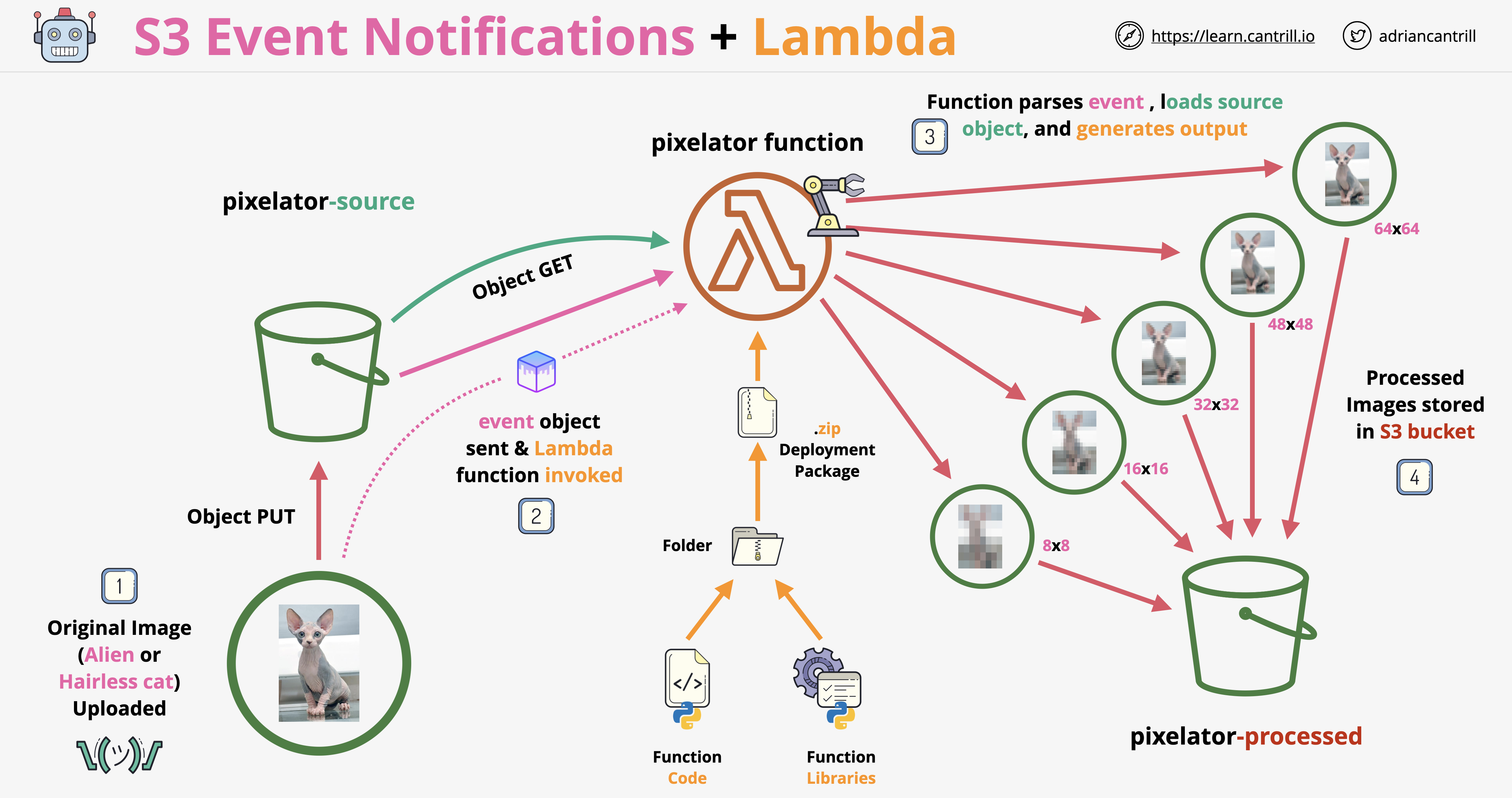
2 S3 buckets
- one to hold source images
- the other for processed images
IAM Role for Lambda function
- We use a policy document to specify permissions for this one
- This is done by creating an inline policy, in the
role detailspage
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::REPLACEME-processed",
"arn:aws:s3:::REPLACEME-processed/*",
"arn:aws:s3:::REPLACEME-source/*",
"arn:aws:s3:::REPLACEME-source"
]
},
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:us-east-1:YOURACCOUNTID:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:YOURACCOUNTID:log-group:/aws/lambda/pixelator:*"
]
}
]
}
Create Lambda deployment zip
This is to add python dependencies that are not available in the default python runtime environment in the lambdas.
- Namely:
from PIL import ImageFirst download & unzip
PILinto folder withlambda_function.pydelete the downloaded zip with PIL
zip your working directory (lamda_function.py & the unzipped PIL stuff) and that’s it.
zip -r ../my-deployment-package.zip .
The laambda function (inside joke context)
- create the ting
- upload deployment zip
- create environment variables
- change the timeout from default of 3 sec to a more appropriate for this use case, 1 minute.
- our trigger is an object create event from S3 - this is what invokes the function
Recursive invocation If your function writes objects to an S3 bucket, ensure that you are using different S3 buckets for input and output. Writing to the same bucket increases the risk of creating a recursive invocation, which can result in increased Lambda usage and increased costs
The python code
import os
import json
import uuid
import boto3
from PIL import Image
# bucketname for pixelated images
processed_bucket=os.environ['processed_bucket']
s3_client = boto3.client('s3')
def lambda_handler(event, context):
print(event)
# get bucket and object key from event object
source_bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# Generate a temp name, and set location for our original image
object_key = str(uuid.uuid4()) + '-' + key
img_download_path = '/tmp/{}'.format(object_key)
# Download the source image from S3 to temp location within execution environment
with open(img_download_path,'wb') as img_file:
s3_client.download_fileobj(source_bucket, key, img_file)
# Biggify the pixels and store temp pixelated versions
pixelate((8,8), img_download_path, '/tmp/pixelated-8x8-{}'.format(object_key) )
pixelate((16,16), img_download_path, '/tmp/pixelated-16x16-{}'.format(object_key) )
pixelate((32,32), img_download_path, '/tmp/pixelated-32x32-{}'.format(object_key) )
pixelate((48,48), img_download_path, '/tmp/pixelated-48x48-{}'.format(object_key) )
pixelate((64,64), img_download_path, '/tmp/pixelated-64x64-{}'.format(object_key) )
# uploading the pixelated version to destination bucket
upload_key = 'pixelated-{}'.format(object_key)
s3_client.upload_file('/tmp/pixelated-8x8-{}'.format(object_key), processed_bucket,'pixelated-8x8-{}'.format(key))
s3_client.upload_file('/tmp/pixelated-16x16-{}'.format(object_key), processed_bucket,'pixelated-16x16-{}'.format(key))
s3_client.upload_file('/tmp/pixelated-32x32-{}'.format(object_key), processed_bucket,'pixelated-32x32-{}'.format(key))
s3_client.upload_file('/tmp/pixelated-48x48-{}'.format(object_key), processed_bucket,'pixelated-48x48-{}'.format(key))
s3_client.upload_file('/tmp/pixelated-64x64-{}'.format(object_key), processed_bucket,'pixelated-64x64-{}'.format(key))
def pixelate(pixelsize, image_path, pixelated_img_path):
img = Image.open(image_path)
temp_img = img.resize(pixelsize, Image.BILINEAR)
new_img = temp_img.resize(img.size, Image.NEAREST)
new_img.save(pixelated_img_path)
Architecture diagram